Clustering, classification, and anomaly detection are fundamental machine learning techniques applied extensively in Business Intelligence (BI) to extract meaningful patterns and insights from data. These techniques enable organizations to segment data, make predictive decisions, and identify unusual behaviors or outliers that may signify risks or opportunities.
Clustering: Grouping Similar Data
Clustering is an unsupervised learning technique that partitions data into groups (“clusters”) based on similarity without pre-labeled outcomes.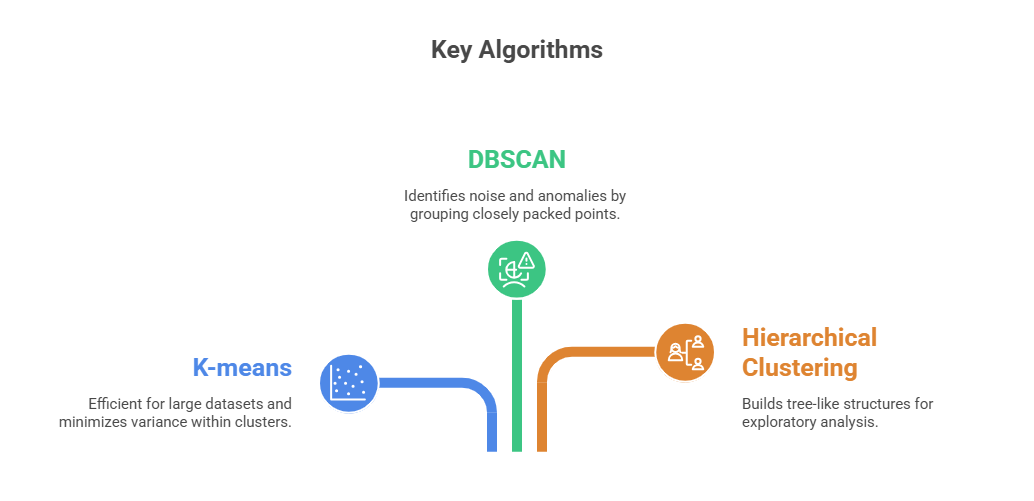
Applications in BI:
1. Customer segmentation to tailor marketing strategies.
2. Grouping similar product preferences or behavior patterns.
3. Data reduction and feature engineering for further analysis.
Best Practices: Handling missing data through appropriate imputation methods to maintain model reliability. Applying dimensionality reduction techniques, such as PCA, helps manage high-dimensional datasets and improve clustering performance. Additionally, assessing cluster quality with metrics like silhouette scores ensures meaningful and well-separated groupings.
Classification: Predicting Categories
Classification is a supervised learning technique where models learn from labeled data to predict categorical outcomes for new data.
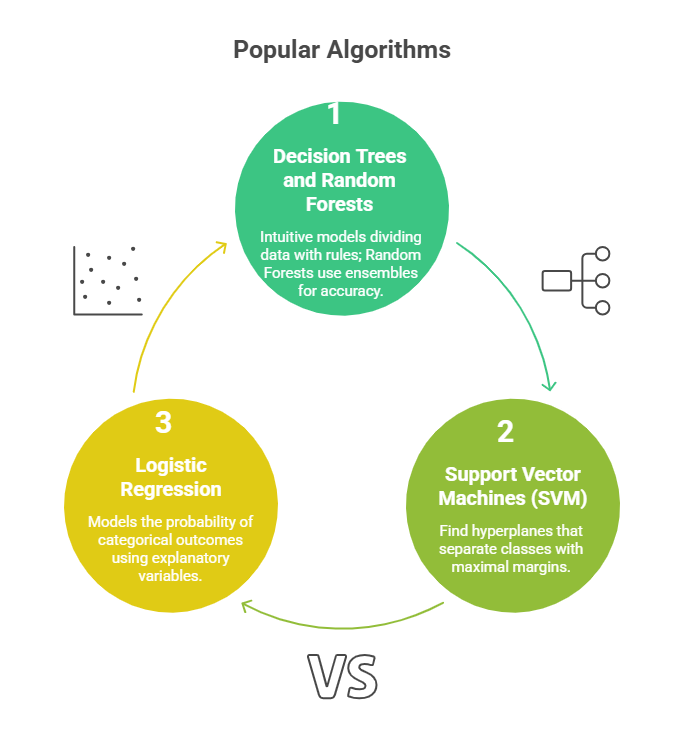
Applications in BI:
1. Fraud detection by classifying transactions as legitimate or suspicious.
2. Customer churn prediction.
3. scoring.
Best Practices: Preprocessing data to balance classes and eliminate noise, ensuring cleaner and more reliable model inputs. Cross-validating models helps assess robustness across different data splits, while applying feature selection improves both performance and interpretability.
Anomaly Detection: Identifying Deviations
Anomaly detection identifies unusual instances or outliers in datasets that deviate from expected behavior.
.png)
Applications in BI:
1. Detecting fraud, network intrusions, and operational failures.
2. Quality control in manufacturing.
3. Monitoring unusual customer behavior or transactions.
Best Practices: Combining multiple detection techniques to improve accuracy and reduce false results. Continuously updating models with new data ensures they adapt to evolving patterns, while incorporating domain expertise helps validate findings and enhance overall reliability.
