ETL—Extract, Transform, Load—is a foundational process in Business Intelligence (BI) and data warehousing that enables the movement of data from diverse sources into a centralised data repository designed for analysis.
ETL processes ensure that data is extracted from source systems, transformed into a clean and usable format, and loaded into target storage such as data warehouses or data marts. Automation of ETL pipelines further enhances efficiency, consistency, and scalability, allowing organisations to process large volumes of data with minimal manual intervention.
Understanding the ETL Process
ETL involves three key phases:
1. Extract
Data extraction involves gathering data from multiple heterogeneous sources, including databases, applications, files, APIs, and streaming platforms. Extraction must be optimised to avoid impacting source system performance and to handle varying data formats and structures. Techniques include full extraction, incremental extraction, and change data capture (CDC) to capture only data changes.
2. Transform
Transformation makes raw data clean, consistent, and analysis-ready. This phase involves:.png)
Transformation logic ensures compatibility with target schemas and meets specific business requirements.
3. Load
In the loading phase, transformed data is inserted, updated, or deleted in the target database or warehouse. This phase requires efficient batch or streaming processes to minimise latency and maintain system performance. Load strategies include full load, incremental load, and real-time loading depending on use cases.
Pipeline Automation in ETL
Automating ETL pipelines significantly improves reliability, reduces errors, and frees up resources. Key aspects of pipeline automation include:
1. Workflow Orchestration: Automation tools (e.g., Apache Airflow, AWS Glue) schedule, monitor, and manage dependencies between ETL tasks.
2. Error Handling and Logging: Automated pipelines capture errors, send alerts, and provide detailed logs for troubleshooting.
3. Scalability: Automation supports scaling horizontally and vertically, dynamically allocating resources based on workloads.
4. Parameterization and Reusability: ETL jobs can be parameterized for varying inputs and reused across projects to accelerate development.
5. Continuous Integration/Continuous Deployment (CI/CD): ETL pipelines are integrated into CI/CD cycles for rapid deployment and version control.
Automation minimizes manual interventions, improving operational efficiency and enabling near real-time data processing when necessary.
Benefits of ETL and Automation
Well-implemented ETL automation transforms raw data into actionable insights with speed and precision. Below are several notable benefits illustrating its impact on business operations:
1. Ensures data quality and consistency across an enterprise
2. Accelerates data availability to analytics and reporting teams
3. Supports complex data transformations that manual processes cannot reliably handle
4. Improves operational efficiency by reducing manual workload
5. Enables real-time or near real-time data updates to meet dynamic business needs
6. Reduces risks associated with manual errors and process failures
Common ETL Tools and Technologies
Numerous ETL tools support pipeline automation and sophisticated transformation capabilities. Examples include:
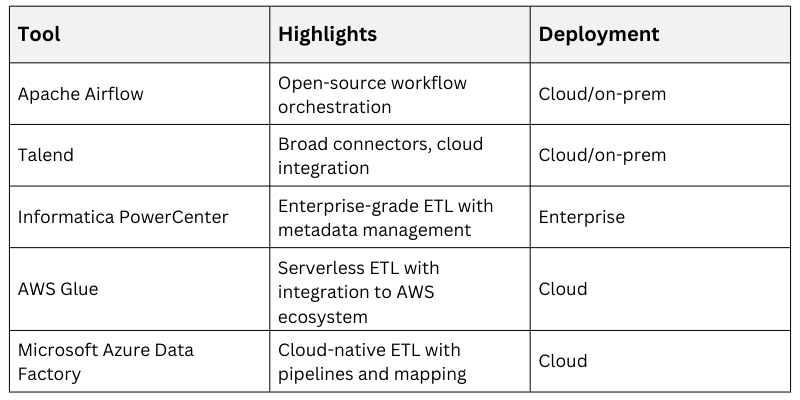
Selection depends on organizational ecosystem, scalability needs, technical skillsets, and budget.
