AWS Lambda is a pioneering serverless compute service that lets developers run their code without managing or provisioning servers.
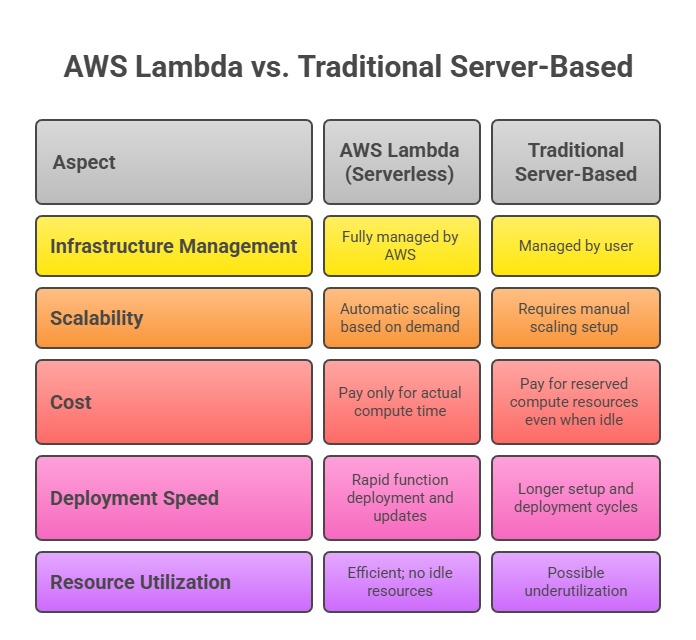
The core advantage of serverless computing is the abstraction of infrastructure management—developers focus solely on writing and deploying code, while AWS handles the underlying server provisioning, patching, scaling, and maintenance.
This model helps to drastically reduce operational overhead and cost, providing a highly responsive and scalable solution for modern applications.
How AWS Lambda Works
Lambda operates on an event-driven architecture, meaning functions run only in response to specific triggers or events.
These events can originate from numerous AWS services or custom sources, such as file uploads to Amazon S3, database table updates in DynamoDB, HTTP requests through API Gateway, or messages from queues like Amazon SQS.
Once triggered, Lambda executes the function code in a managed execution environment, automatically scaling to handle the number of events without manual intervention.
Key Features of AWS Lambda
1. No Server Management: AWS handles all infrastructure operations, eliminating the need for server provisioning or maintenance.
2. Automatic Scaling: Lambda dynamically adjusts capacity to handle event rates, scaling from zero to thousands of concurrent executions seamlessly.
3. Pay-per-Use Pricing: Billing is based on the number of requests and function execution time, measured in milliseconds, which optimizes costs.
4. Stateless Execution: Functions are stateless and ephemeral; any required persistent data should be stored in external services like S3 or DynamoDB.
5. Flexible Language Support: Lambda supports multiple runtimes, including Node.js, Python, Java, Go, and custom runtimes via container images.
6. Integrated Security: Execution roles and IAM policies control permissions and secure access to AWS resources and APIs.
Use Cases for AWS Lambda
From data processing to API integrations, AWS Lambda adapts to dynamic workloads with efficiency and speed. Here are several use cases illustrating its impact across cloud-based operations:
1. Data Processing: Transform, filter, and aggregate data streams or file uploads automatically.
2. Backend Services: Power web and mobile application backends without server management.
3. Real-Time File and Image Processing: Automatically resize images, process logs, or handle data ETL jobs on demand.
4. Event-Driven Automation: Orchestrate workflows, respond to IoT sensor data, and automate infrastructure tasks.
5. API Integration: Build RESTful APIs with Amazon API Gateway, triggering Lambda for business logic execution.
Stateless Nature and Best Practices
AWS Lambda functions are designed to be stateless and short-lived, which supports high concurrency and portability. For any data persistence needs, interaction with database services (DynamoDB, RDS) or storage (S3) is essential.
Developers should design functions to be idempotent, ensuring safe retries in case of failures. Careful planning around cold starts, function timeout, and memory allocation can optimise performance and costs.
Integration with Other AWS Services
AWS Lambda integrates deeply with AWS ecosystem components, such as:
1. Amazon S3 (to trigger functions on file events)
2. Amazon DynamoDB Streams (to process database changes)
3. Amazon API Gateway (to create API backends)
4. AWS Step Functions (to orchestrate serverless workflows)
5. Amazon CloudWatch (to monitor logs and metrics)
