Machine Learning (ML)
Machine Learning (ML) is a subfield of artificial intelligence (AI) that focuses on developing algorithms and statistical models that enable computers to learn patterns, relationships, and insights from data without being explicitly programmed for every specific task. Unlike traditional programming, where a developer writes explicit instructions for the computer, ML allows systems to improve their performance automatically through experience. In ML, computers are trained on datasets, which can be structured, unstructured, or semi-structured, to recognize patterns, make predictions, or take actions based on input data.
At its core, Machine Learning relies on mathematical and statistical principles to detect patterns in data, estimate probabilities, and generalize findings to unseen data. This capability enables ML systems to perform tasks such as classification, regression, clustering, anomaly detection, and recommendation in a wide range of applications. ML algorithms are generally categorized into supervised learning, where models are trained with labeled data; unsupervised learning, where models identify hidden structures in unlabeled data; semi-supervised learning, which combines labeled and unlabeled data; and reinforcement learning, where models learn optimal actions through trial-and-error interactions with an environment.
Machine Learning plays a critical role in modern technology, powering systems such as image and speech recognition, natural language processing, autonomous vehicles, predictive analytics, healthcare diagnostics, financial forecasting, and recommendation engines. By enabling systems to learn from data and adapt to new situations, ML reduces human effort, improves accuracy, and provides scalable solutions to complex real-world problems. It is a continuously evolving field that integrates concepts from computer science, statistics, data science, and domain-specific knowledge to create intelligent systems capable of autonomous decision-making.
Importance of Machine Learning
Machine Learning has become a cornerstone of modern technology due to its ability to enable systems to learn from data, improve over time, and make intelligent decisions. Its importance spans multiple domains, providing efficiency, accuracy, and scalability to real-world applications. Below are the key aspects highlighting why ML is essential today:
1. Automation of Complex Tasks
Machine Learning allows computers to perform tasks that traditionally required human intelligence, such as recognizing patterns, interpreting data, or making decisions. By learning from historical data, ML systems can automate processes like document classification, predictive maintenance, and customer support chatbots. This automation reduces manual effort, saves time, and allows humans to focus on more strategic and creative tasks.
2. Enhanced Accuracy and Decision Making
ML algorithms analyze vast amounts of data and identify trends, correlations, and anomalies that may be imperceptible to humans. By continuously learning from data, these systems improve their predictions and recommendations over time. For example, ML is used in healthcare to detect diseases early, in finance to predict market trends, and in business to forecast demand. This ability to make accurate, data-driven decisions enhances reliability and reduces human error.
3. Handling Large and Complex Datasets
Modern organizations generate enormous volumes of structured and unstructured data. Traditional analytical methods often fail to process and extract insights from such data efficiently. Machine Learning excels in handling large-scale datasets, identifying patterns, and converting raw data into actionable knowledge. This capacity is crucial in fields like e-commerce, social media analytics, and scientific research, where understanding massive datasets drives strategic decisions.
4. Adaptability and Continuous Learning
One of the key strengths of ML is adaptability. Unlike static software, ML models can evolve as new data becomes available. This continuous learning allows systems to remain relevant, improve over time, and adapt to changing environments or behaviors. For instance, recommendation systems in streaming platforms like Netflix or Spotify adjust suggestions based on users’ evolving preferences, enhancing personalization and engagement.
5. Enabling Predictive Analytics
Machine Learning is the backbone of predictive analytics, allowing organizations to anticipate future events and trends. By analyzing historical data and recognizing patterns, ML models can predict outcomes such as customer churn, equipment failure, or stock prices. These predictive capabilities help organizations make proactive decisions, optimize operations, and gain competitive advantages.
6. Driving Innovation Across Industries
ML is a driving force for innovation in diverse fields, from autonomous vehicles and robotics to natural language processing and medical imaging. It enables the development of intelligent systems that were previously impossible, such as self-driving cars that interpret sensor data in real time or AI-assisted diagnostic tools that support doctors in detecting diseases accurately. By leveraging ML, industries can create smarter products, services, and solutions that transform how we live and work.
7. Cost Reduction and Efficiency Improvement
Implementing ML in business processes can lead to significant cost savings and operational efficiency. Automated systems reduce the need for manual intervention, minimize errors, and optimize resource allocation. For example, ML-powered supply chain optimization predicts demand more accurately, reducing inventory costs, and ML-based fraud detection prevents financial losses in banking and e-commerce.
Machine Learning’s importance stems from its ability to empower systems with intelligence, enabling them to learn, adapt, and make decisions autonomously. By automating tasks, improving accuracy, handling large datasets, providing predictive insights, fostering innovation, and increasing operational efficiency, ML has become indispensable in modern technology, research, and industry. Its integration with AI, big data, and cloud computing continues to expand its potential, making it a transformative force in solving complex real-world problems.
Machine Learning with Python
Machine Learning (ML) with Python refers to using Python programming language and its ecosystem of libraries to implement intelligent systems capable of learning from data. Python is the most popular language for ML due to its simplicity, readability, extensive libraries, and community support. With Python, developers can preprocess data, build models, train them, evaluate performance, and deploy solutions efficiently. Python libraries like scikit-learn, TensorFlow, PyTorch, NumPy, and pandas provide tools for all stages of ML, from data handling to advanced neural networks.
Types of Machine Learning
Machine Learning can be broadly categorized into four main types, based on how models learn from data and the type of feedback they receive. Each type is suited to different kinds of problems and applications. Python and its ML libraries provide tools to implement all these types efficiently.
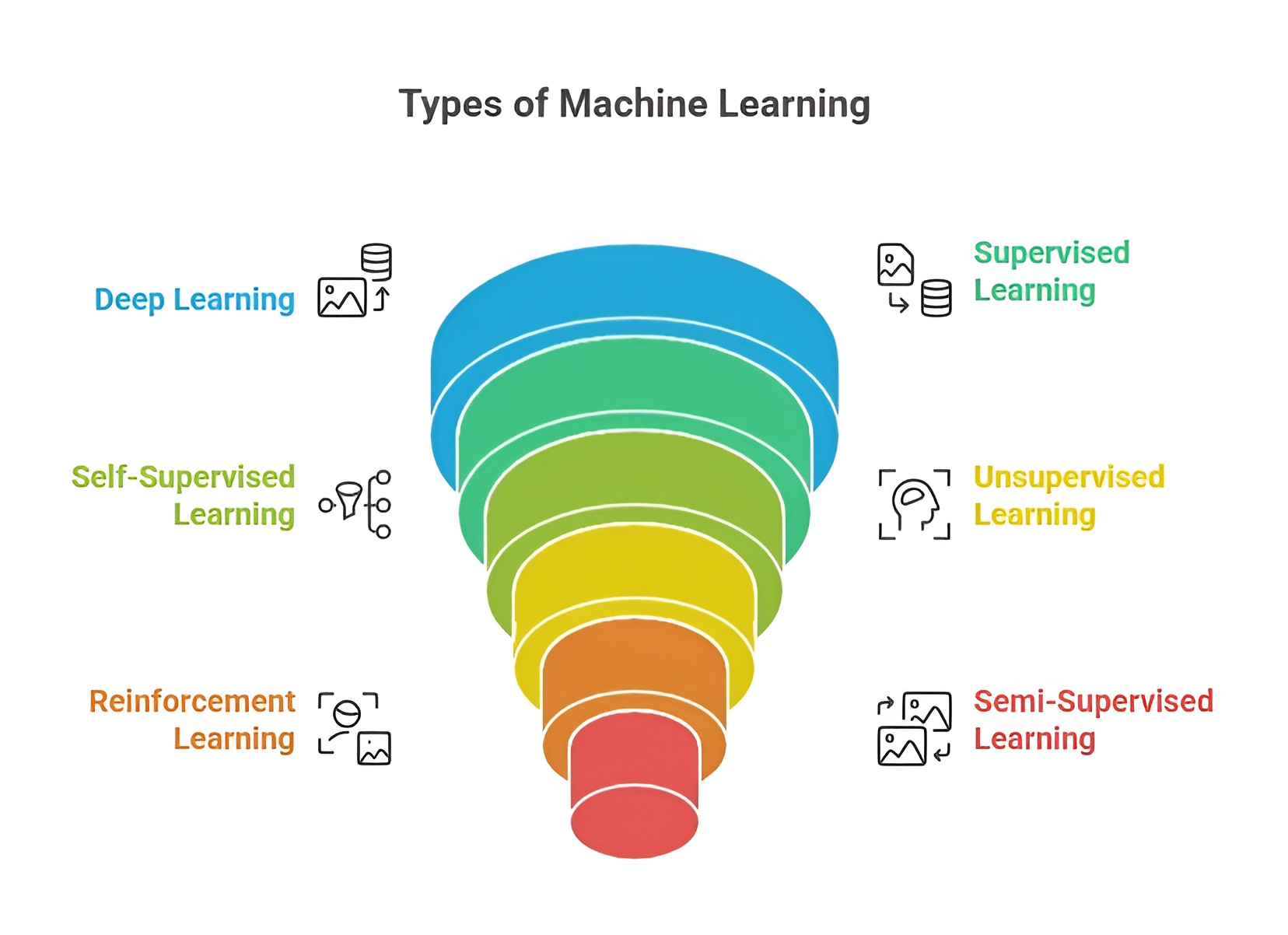
1. Supervised Learning
Supervised learning is a branch of ML in which models are trained on labeled datasets, where each input comes with a corresponding output or target. The goal is to learn a mapping from inputs to outputs so that the model can predict the output for new, unseen data. Supervised learning is widely used in predictive tasks and decision-making systems. Python provides multiple tools for implementing supervised learning using libraries such as scikit-learn.
1.1 Regression
Regression is a type of supervised learning used when the output variable is continuous. The model learns to predict numerical values based on input features. Examples include predicting house prices, stock values, or temperature trends. Linear regression is one of the simplest regression techniques, which fits a line through the data points to minimize the error. Python’s LinearRegression from scikit-learn allows easy implementation of regression models.
from sklearn.linear_model import LinearRegression
import numpy as np
X = np.array([[1], [2], [3], [4]])
y = np.array([2, 4, 6, 8])
model = LinearRegression()
model.fit(X, y)
prediction = model.predict([[5]])
print(prediction) # Output: [10.]
1.2 Classification
Classification is another type of supervised learning used when the output variable is categorical. The model learns to assign inputs to specific classes. Common applications include spam detection, sentiment analysis, and image recognition. Algorithms like Logistic Regression, Decision Trees, Random Forests, and Support Vector Machines (SVM) are popular in Python for classification tasks.
from sklearn.tree import DecisionTreeClassifier
X = [[0, 0], [1, 1]]
y = [0, 1]
clf = DecisionTreeClassifier()
clf.fit(X, y)
print(clf.predict([[2, 2]])) # Output: [1]
2. Unsupervised Learning
Unsupervised learning deals with unlabeled datasets, where the model tries to identify hidden patterns, structures, or relationships in the data. Unlike supervised learning, there are no predefined outputs, and the goal is exploratory analysis or clustering similar data points. Python provides tools like scikit-learn for unsupervised learning techniques.
2.1 Clustering
Clustering is an unsupervised learning method that groups similar data points into clusters based on feature similarity. It is widely used in customer segmentation, market research, anomaly detection, and image segmentation. Popular clustering algorithms include K-Means, Hierarchical Clustering, and DBSCAN. Python allows easy implementation of clustering using KMeans from scikit-learn.
from sklearn.cluster import KMeans
X = [[1, 2], [1, 4], [1, 0], [10, 2], [10, 4], [10, 0]]
kmeans = KMeans(n_clusters=2, random_state=0).fit(X)
print(kmeans.labels_) # Output: [1 1 1 0 0 0]
2.2 Dimensionality Reduction
Dimensionality reduction is used to reduce the number of input features while retaining important information. It helps in visualizing high-dimensional data, speeding up training, and improving model performance. Techniques like Principal Component Analysis (PCA) and t-SNE are widely used. Python’s PCA in scikit-learn simplifies this process.
from sklearn.decomposition import PCA
X = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
pca = PCA(n_components=2)
reduced = pca.fit_transform(X)
print(reduced)
3. Reinforcement Learning
Reinforcement learning (RL) is a branch of ML where an agent learns to make decisions by interacting with an environment. The agent takes actions to maximize cumulative rewards based on feedback received from the environment. RL is widely used in robotics, game AI, autonomous vehicles, and resource optimization. Python frameworks like OpenAI Gym and libraries like Stable Baselines help implement RL models, where the agent learns optimal strategies over time using trial-and-error.
Key components of RL include states (current situation of the agent), actions (possible moves), rewards (feedback for actions), and policy (strategy to maximize rewards).
# Basic RL environment example
import gym
env = gym.make('CartPole-v1')
state = env.reset()
print(state) # Initial state observation
Machine Learning with Python allows developers and researchers to analyze data, build predictive models, and create intelligent systems efficiently. Python’s rich ecosystem of libraries, simplicity, and active community support makes it the preferred choice for implementing supervised learning (regression and classification), unsupervised learning (clustering and dimensionality reduction), and reinforcement learning. By understanding these concepts and using Python’s tools, one can develop robust ML solutions applicable in finance, healthcare, e-commerce, robotics, and many other domains.
