Deep Learning
Deep Learning is a specialized branch of machine learning that focuses on algorithms inspired by the structure and function of the human brain, known as artificial neural networks. Unlike traditional machine learning techniques that rely on manually engineered features, deep learning models automatically learn hierarchical representations of data, capturing complex patterns and relationships. These models typically consist of multiple layers—input, hidden, and output layers—which progressively extract higher-level features from raw data, enabling tasks such as image recognition, natural language processing, speech recognition, and autonomous driving. Deep learning has gained prominence due to its ability to process large volumes of data, achieve high accuracy, and power modern artificial intelligence applications across diverse domains.
Importance of Deep Learning
Deep Learning is a transformative technology that drives many modern AI applications. Its significance lies in its ability to automatically extract complex patterns from data and perform tasks that traditionally required human intelligence. Below is a detailed explanation of its importance, with definitions and applications under each heading.
1. Automatic Feature Extraction
Deep Learning models automatically learn features and representations from raw data without requiring manual feature engineering. In traditional machine learning, significant human effort is spent designing features to represent data meaningfully. Deep learning networks, especially convolutional neural networks (CNNs) and recurrent neural networks (RNNs), can identify hierarchical and intricate features in images, audio, text, or time-series data, allowing for more accurate and scalable solutions.
Example: In image recognition, a CNN automatically learns edges, textures, and object parts without manually coding these patterns.
2. High Accuracy and Performance
Deep Learning models are capable of achieving high levels of accuracy in complex tasks because they can learn from large-scale datasets and model nonlinear relationships. With sufficient training data, deep learning networks outperform traditional algorithms in tasks like object detection, language translation, and speech recognition, making them indispensable in AI-driven systems.
Example: Voice assistants like Siri and Google Assistant rely on deep learning for precise speech-to-text conversion.
3. Handling Unstructured Data
A key advantage of deep learning is its ability to process unstructured data, such as images, videos, audio, and natural language, which cannot be easily handled by traditional machine learning models. Deep learning networks transform raw data into meaningful representations and extract useful information, enabling automation and intelligent decision-making in scenarios where structured data is not available.
Example: Social media platforms use deep learning to analyze videos and images for content moderation or recommendation.
4. Real-Time and Scalable Applications
Deep learning architectures, particularly those optimized for GPU acceleration, can process massive amounts of data in real time. This enables scalable solutions in industries such as autonomous driving, healthcare, and robotics, where rapid and accurate decision-making is crucial.
Example: Self-driving cars use deep learning to detect pedestrians, vehicles, and traffic signs in real time for safe navigation.
5. Enabling Advanced AI Applications
Deep learning is the foundation for many cutting-edge AI applications, including natural language processing (NLP), computer vision, speech recognition, and recommendation systems. By learning complex relationships and patterns from data, it enables machines to perform tasks that previously required human intelligence, bringing AI closer to human-like capabilities.
Example: Chatbots, virtual assistants, and AI translators rely on deep learning models like transformers to understand and generate human language.
6. Continuous Improvement with Data
Deep learning systems improve their performance as they are exposed to more data, thanks to their hierarchical learning architecture. This makes them highly adaptive and capable of evolving over time, providing long-term value in dynamic environments.
Example: Recommendation engines in platforms like Netflix or YouTube continuously learn user preferences and improve content suggestions.
Deep learning libraries
Deep Learning libraries are specialized software frameworks that provide pre-built functions, models, and tools to develop, train, and deploy deep neural networks efficiently. These libraries abstract the complex mathematics and computations involved in neural network operations, allowing developers and researchers to focus on designing architectures, experimenting with data, and implementing AI solutions. They support automatic differentiation, GPU acceleration, and modular design, making it easier to build large-scale, high-performance models for tasks such as image recognition, natural language processing, speech synthesis, and autonomous systems. Popular deep learning libraries not only provide flexibility for custom model creation but also include pre-trained models, utilities, and visualization tools, enabling rapid development and deployment in research, industry, and real-world applications.
1. TensorFlow
TensorFlow is an open-source deep learning and machine learning framework developed by Google for building, training, and deploying artificial intelligence models. It provides a comprehensive ecosystem for designing neural networks, from simple linear models to complex deep learning architectures such as convolutional neural networks (CNNs), recurrent neural networks (RNNs), and transformers. TensorFlow is designed to handle large-scale numerical computations efficiently, using dataflow graphs where nodes represent mathematical operations and edges represent multi-dimensional data arrays called tensors. This structure allows TensorFlow to perform automatic differentiation, optimize computations, and leverage hardware acceleration, including GPUs and TPUs, for faster model training and inference. Beyond deep learning, TensorFlow supports deployment across multiple platforms, including desktop, web, mobile (TensorFlow Lite), and cloud environments, making it highly versatile for real-world AI applications. With built-in tools for visualization (TensorBoard), pre-trained models (TensorFlow Hub), and data handling, TensorFlow simplifies the development pipeline, enabling both researchers and developers to create robust, scalable, and high-performance AI solutions efficiently.
2.Pytorch
PyTorch is an open-source deep learning framework developed by Meta that is known for its flexibility and dynamic computation graphs. It allows developers to build and train neural networks easily with a Python-friendly interface. PyTorch supports GPU acceleration for faster training and experimentation. Its dynamic nature makes debugging and model customization simpler. Today, PyTorch is widely used in research, computer vision, NLP, and cutting-edge AI development.
Importance of TensorFlow
TensorFlow is one of the most versatile and widely adopted frameworks for deep learning and artificial intelligence (AI) development. Its significance lies in providing developers and researchers with the tools to design, train, and deploy neural networks and machine learning models efficiently. TensorFlow supports complex computations, large datasets, and multiple deployment environments, making it a backbone for modern AI applications across industries such as healthcare, finance, robotics, autonomous systems, and natural language processing.
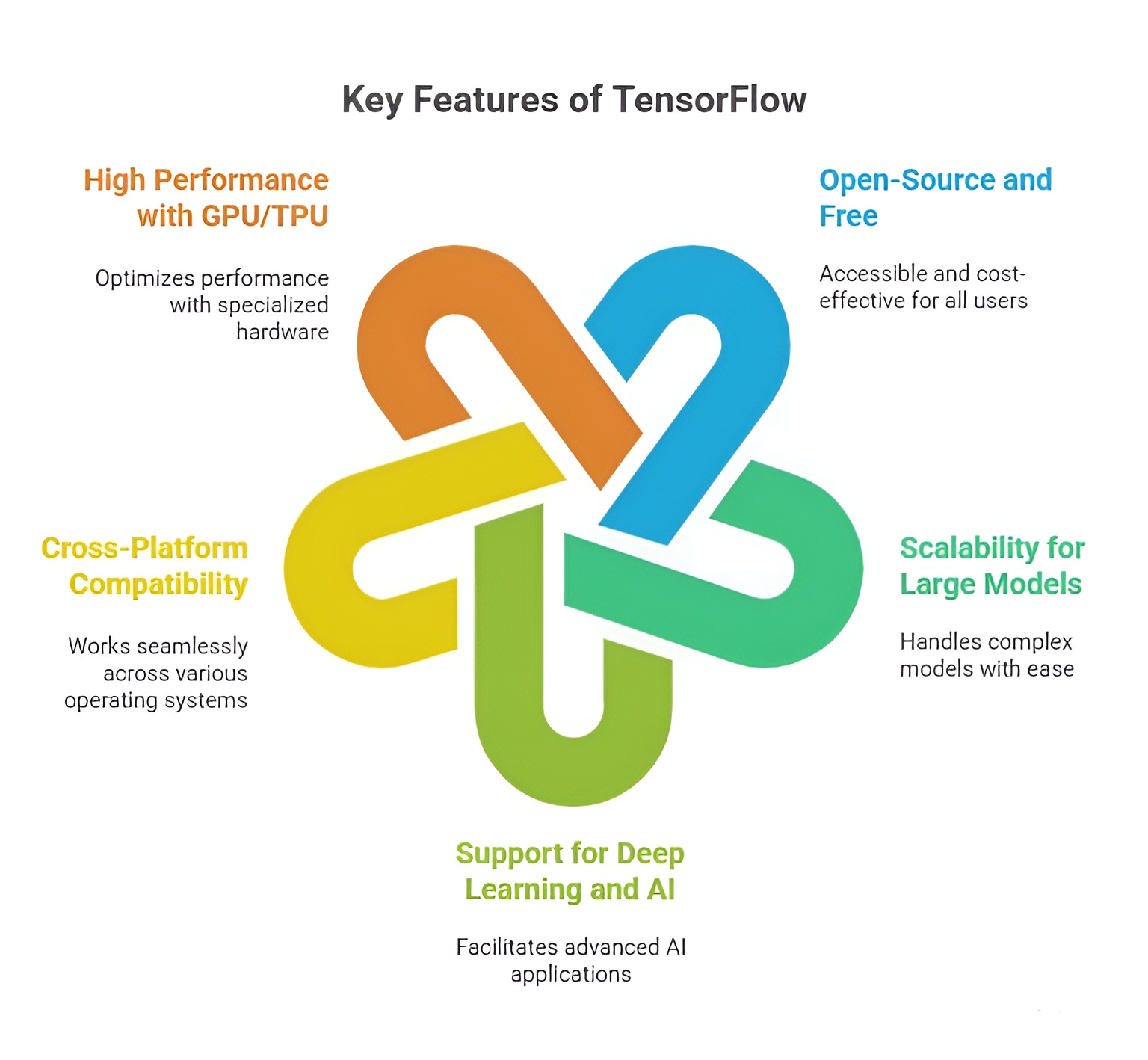
1. Open-Source and Free to Use
TensorFlow being open-source means that it is freely available for anyone to use, modify, and distribute. This open nature encourages a collaborative community where researchers and developers contribute improvements, share pre-trained models, and create tutorials. It ensures accessibility for beginners and small-scale developers while also being robust enough for enterprise-level projects. The open-source ecosystem also accelerates innovation in AI by providing reusable modules and standardised practices.
2. Support for Multiple Platforms
TensorFlow is platform-agnostic, allowing AI models to run on desktops, cloud servers, mobile devices, and web applications. TensorFlow Lite optimizes models for mobile deployment, while TensorFlow Serving ensures seamless integration for cloud-based applications. This multi-platform support allows a single model to be reused across different devices and environments, eliminating the need to rewrite code for various platforms and enhancing the practicality of AI solutions in real-world scenarios.
3. Scalability for Large-Scale Projects
TensorFlow is designed to handle both small research experiments and large-scale industrial AI projects. Its distributed computing support allows training of neural networks across multiple GPUs or TPUs, enabling efficient handling of massive datasets and complex models. This scalability is crucial for enterprises that need to deploy AI solutions for predictive analytics, automated decision-making, or recommendation systems, where performance and throughput are key considerations.
4. High Performance with Hardware Acceleration
TensorFlow can leverage specialized hardware like GPUs and TPUs to accelerate numerical computations and deep learning training. Hardware acceleration drastically reduces the time required to train models on large datasets, enabling faster iterations and experimentation. This high-performance capability is particularly important for applications that require real-time processing, such as image recognition, autonomous driving, natural language understanding, and speech recognition.
5. Comprehensive Ecosystem and Tools
TensorFlow provides a rich ecosystem that supports the full lifecycle of AI development. TensorBoard offers visualization and monitoring of model training, TensorFlow Hub provides pre-trained models for quick experimentation, and TensorFlow Extended (TFX) allows robust production pipelines. TensorFlow Lite facilitates deployment on mobile and edge devices. This extensive toolset simplifies the development, evaluation, and deployment of AI models, reducing development time and enabling consistent, production-ready solutions.
6. Support for Multiple Languages
While Python is the primary language for TensorFlow, it also provides APIs for C++, Java, JavaScript (TensorFlow.js), and Swift. This allows developers to integrate AI models into a wide variety of applications, from web and mobile apps to embedded systems. Multi-language support broadens the reach of AI, enabling its adoption across different industries and technology stacks without limiting developers to a single programming environment.
7. Flexibility for Custom Model Design
TensorFlow is not limited to standard neural network architectures. Developers can define custom layers, activation functions, and loss functions to create novel models tailored to specific tasks. This flexibility supports experimentation, research, and the development of innovative AI solutions in areas such as reinforcement learning, generative models, and advanced computer vision. TensorFlow’s adaptability makes it suitable for both academic research and cutting-edge industrial applications.
Basics of TensorFlow
TensorFlow is a comprehensive, open-source framework for numerical computation and machine learning, developed by Google. It is designed to perform large-scale computations efficiently on tensors, which are multi-dimensional arrays that generalize scalars, vectors, and matrices to higher dimensions. TensorFlow’s architecture supports distributed computation across CPUs, GPUs, and TPUs, making it suitable for both research experiments and production-level applications. It is widely used in computer vision, natural language processing, reinforcement learning, and other AI domains due to its flexibility, scalability, and extensive ecosystem of pre-built tools and libraries.
Tensors
A tensor is a fundamental data structure in TensorFlow, representing data in one or more dimensions. Tensors can range from scalars (0D) to vectors (1D), matrices (2D), and higher-dimensional data such as images (3D or 4D with batch size and channels). Each tensor has a shape, indicating the size of each dimension, and a rank, specifying the number of dimensions. Tensors are immutable by default when defined as constants, but TensorFlow also provides variables for mutable tensors, which are crucial for representing trainable model parameters like weights and biases.
For example, a scalar tensor is defined as:
import tensorflow as tf
scalar = tf.constant(5)
print(scalar) # Output: tf.Tensor(5, shape=(), dtype=int32)
A 2D tensor (matrix) example:
matrix = tf.constant([[1, 2], [3, 4]])
print(matrix)
# Output: tf.Tensor(
# [[1 2]
# [3 4]], shape=(2, 2), dtype=int32)
Mutable tensors can be created using tf.Variable:
variable_tensor = tf.Variable([[1, 2], [3, 4]])
variable_tensor.assign([[5, 6], [7, 8]])
print(variable_tensor)
Tensors are the backbone of all computations in TensorFlow and allow seamless operations on high-dimensional data like images, videos, or time-series datasets.
Tensor Operations
TensorFlow supports a variety of tensor operations including arithmetic, reshaping, slicing, and indexing. These operations can be performed element-wise or along specific axes, allowing flexible manipulation of input data. Such operations are essential in preprocessing, data augmentation, and feeding data into machine learning models.
a = tf.constant([[1, 2], [3, 4]])
b = tf.constant([[5, 6], [7, 8]])
# Addition
add_result = tf.add(a, b)
print(add_result) # [[6 8] [10 12]]
# Multiplication
mul_result = tf.multiply(a, b)
print(mul_result) # [[5 12] [21 32]]
# Reshape
reshaped = tf.reshape(a, [4, 1])
print(reshaped) # [[1], [2], [3], [4]]
# Slicing and Indexing
slice_tensor = a[0:1, 1:2]
print(slice_tensor) # [[2]]
These operations are highly optimized to leverage parallel computation on GPUs or TPUs, enabling high-performance processing of large datasets.
Constants, Variables, and Placeholders
In TensorFlow, constants are immutable tensors representing fixed data or parameters. Variables are mutable tensors, commonly used for trainable model parameters such as weights in neural networks. Placeholders were used in TensorFlow 1.x to feed input data dynamically into computation graphs but are largely replaced by tf.data.Dataset pipelines in TensorFlow 2.x, which provide a more intuitive and scalable data input mechanism.
# Constant
c = tf.constant(10)
# Variable
v = tf.Variable(5)
v.assign(15)
# Placeholder (TensorFlow 1.x)
# import tensorflow.compat.v1 as tf
# tf.disable_v2_behavior()
# p = tf.placeholder(tf.float32)
This distinction allows TensorFlow to separate static model structure from dynamic, trainable data, providing both efficiency and flexibility in model design.
Basic Math Functions
TensorFlow provides built-in functions for mathematical computation on tensors. Functions like reduce_sum and reduce_mean help aggregate tensor values, which is critical for computing loss functions, metrics, and other statistical operations during model training.
tensor = tf.constant([[1, 2], [3, 4]])
# Sum of all elements
sum_result = tf.reduce_sum(tensor)
print(sum_result) # 10
# Mean of all elements
mean_result = tf.reduce_mean(tensor)
print(mean_result) # 2.5
These operations are executed efficiently, taking advantage of TensorFlow’s optimized backend, allowing seamless computation on both small and large-scale datasets.
Graphs and Sessions (TensorFlow 1.x Concept)
In TensorFlow 1.x, computations were organized into static computation graphs, where nodes represented operations and edges represented tensors. Execution required a session to evaluate operations, allowing TensorFlow to optimize computation and parallelize tasks. This design facilitated deployment to distributed systems but was less intuitive for beginners.
# TensorFlow 1.x example
# import tensorflow.compat.v1 as tf
# tf.disable_v2_behavior()
# a = tf.constant(5)
# b = tf.constant(10)
# sum_ab = tf.add(a, b)
# with tf.Session() as sess:
# result = sess.run(sum_ab)
# print(result) # 15
TensorFlow 2.x replaces this with eager execution, where operations run immediately and return results without requiring a session. This makes TensorFlow more intuitive, Pythonic, and easier to debug while maintaining the ability to build graphs for performance optimization and deployment.
TensorFlow is not just a library but a complete ecosystem for machine learning and AI. It integrates seamlessly with Keras for high-level model design, supports deployment to mobile and web platforms through TensorFlow Lite and TensorFlow.js, and provides specialized tools for distributed training. Its tensor-based architecture allows automatic differentiation, enabling backpropagation in neural networks. TensorFlow also supports advanced features like custom training loops, dynamic computation graphs, and integration with other frameworks like PyTorch and ONNX, making it highly versatile for modern AI applications.
Data Handling in TensorFlow
Efficient data handling is essential for deep learning models because the structure and quality of input data directly affect model performance. TensorFlow provides a robust framework for managing datasets, preprocessing data, and creating optimized input pipelines through its tf.data API. This API enables developers to load, transform, batch, shuffle, and prefetch data efficiently, allowing models to train faster and more reliably.
1. Using tf.data API
The tf.data API is the core mechanism for building flexible input pipelines. It treats datasets as sequences of tensors and provides functions to transform and prepare the data for training. Using this API, datasets can be created from Python lists, generators, or existing arrays, and operations such as mapping transformations, batching, and prefetching can be applied. This approach ensures that even large datasets that cannot fit entirely into memory can be streamed efficiently during training.
Example: Creating a simple dataset from a Python list and doubling each element:
import tensorflow as tf
data = [1, 2, 3, 4, 5]
dataset = tf.data.Dataset.from_tensor_slices(data)
dataset = dataset.map(lambda x: x * 2)
for item in dataset:
print(item.numpy()) # Output: 2, 4, 6, 8, 10
2. Loading Data from Various Sources
TensorFlow supports multiple data sources, including CSV files, image directories, and TFRecord files. CSV files can be loaded using tf.data.experimental.make_csv_dataset(), which reads tabular data and automatically handles column parsing and batching. Images can be loaded with tf.keras.utils.image_dataset_from_directory(), which resizes images, assigns labels, and batches them automatically. TFRecord files, TensorFlow’s optimized binary format, are ideal for very large datasets and can be read efficiently using tf.data.TFRecordDataset(). These flexible data loading methods make TensorFlow suitable for a wide range of real-world datasets.
3. Data Preprocessing
Preprocessing ensures that the input data is consistent, normalized, and suitable for model consumption. Common preprocessing steps include normalization, which rescales features or image pixels to a standard range; encoding labels, which converts categorical labels to numeric or one-hot formats; and data augmentation, which increases dataset diversity through techniques like rotation, flipping, or cropping. Preprocessing can be applied directly within the dataset pipeline using the map function to automatically transform each sample.
Example: Normalizing images and encoding labels:
def preprocess(image, label):
image = tf.cast(image, tf.float32) / 255.0 # normalize pixel values
label = tf.one_hot(label, depth=10) # one-hot encode labels
return image, label
train_dataset = train_dataset.map(preprocess)
4. Batching, Shuffling, and Prefetching
Optimizing training requires batching, shuffling, and prefetching. Batching groups multiple samples into a single tensor to allow parallel computation, improving GPU efficiency. Shuffling randomizes the order of samples, which reduces overfitting and improves generalization. Prefetching prepares the next batch of data while the current batch is being processed, minimizing idle time and maximising hardware utilization. These steps combined create highly efficient pipelines that accelerate model training.
Example: Applying batching, shuffling, and prefetching:
train_dataset = train_dataset.shuffle(1000) # randomize dataset
train_dataset = train_dataset.batch(32) # batch into 32 samples
train_dataset = train_dataset.prefetch(tf.data.AUTOTUNE) # optimize pipeline
5. Building Complete Dataset Pipelines
A complete dataset pipeline integrates all stages of data handling, from loading to preprocessing, shuffling, batching, and prefetching. This ensures that data is efficiently streamed to the model during training while maintaining high performance and reproducibility. Such pipelines are essential for handling large-scale datasets, automating preprocessing, and minimizing bottlenecks during model training.
Example: Full image dataset pipeline:
train_dataset = tf.keras.utils.image_dataset_from_directory(
"path/to/images",
image_size=(128, 128),
batch_size=32,
label_mode='categorical'
)
train_dataset = train_dataset.map(preprocess)
train_dataset = train_dataset.shuffle(1000)
train_dataset = train_dataset.batch(32)
train_dataset = train_dataset.prefetch(tf.data.AUTOTUNE)
