Pattern recognition and anomaly detection are critical techniques in data analysis and machine learning used to identify regularities and irregularities within datasets.
It involves classifying data into distinct categories based on learned or inherent patterns, enabling the understanding and prediction of behaviors.
Anomaly detection, on the other hand, focuses on identifying data points or events that deviate significantly from expected norms, signaling potential errors, fraud, or emerging issues.
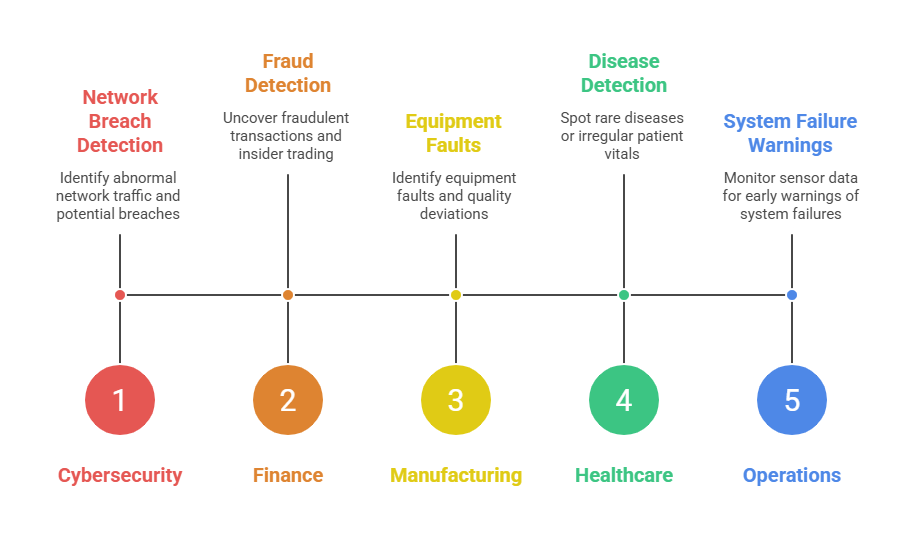
Together, these methods provide complementary insights that help organizations monitor systems, detect risks early, and make proactive decisions in diverse domains such as cybersecurity, finance, healthcare, and manufacturing.
Understanding Pattern Recognition
Pattern recognition is the process of identifying regularities, structures, or recurring sequences in data. It enables classification, clustering, and predictive analytics by grouping similar data points based on features.
Types of Pattern Recognition:
1. Supervised: Uses labeled datasets to learn patterns associated with known classes.
2. Unsupervised: Finds patterns without pre-existing labels using clustering or dimensionality reduction.
3. Semi-Supervised: Combines small labeled data with large unlabeled data to improve learning.
Techniques and Algorithms: Include support vector machines, neural networks, decision trees, hidden Markov models, and deep learning methods.
Applications: Image and speech recognition, natural language processing, customer segmentation, and sensor data interpretation.
Principles of Anomaly Detection
Anomaly detection identifies rare events or data points that don’t conform to expected behavior. These anomalies can indicate significant incidents such as fraud, network intrusions, system faults, or unusual customer behavior.
Types of Anomalies:
1. Point Anomalies: Single data points that are outliers.
2. Contextual Anomalies: Data points that are abnormal in specific contexts, especially in time series.
3. Collective Anomalies: A group of related data points that collectively deviate.
Detection Methods:
1. Statistical Approaches: Use measures like z-scores and interquartile ranges to label outliers.
2. Machine Learning: Supervised models trained on labeled anomalies, and unsupervised methods like clustering and isolation forests.
3. Deep Learning: Autoencoders and recurrent neural networks for complex, high-dimensional data.
Challenges: Balancing false positives and false negatives, handling imbalanced datasets, and adapting to evolving norms.