Measuring DevOps Success
Measuring DevOps success involves evaluating how effectively teams deliver software with speed, quality, and reliability. It relies on metrics like deployment frequency, lead time, change failure rate, and recovery time to assess performance. Success is also gauged by improvements in collaboration, automation, and customer satisfaction. By analyzing these factors, organizations can identify areas for continuous improvement and optimize their DevOps practices.
Key DevOps Metrics (DORA Metrics)
The DORA (DevOps Research and Assessment) metrics are widely recognized as the industry standard for evaluating DevOps performance. These metrics provide objective, quantifiable measures of how well DevOps practices are implemented and their impact on software delivery. Each metric addresses a distinct aspect of performance, from the speed and frequency of deployments to system reliability and operational resilience, enabling organizations to focus on both efficiency and quality.
 - visual selection.png)
1. Deployment Frequency (DF)
Deployment Frequency measures how often code changes are successfully deployed to production or delivered to end-users. High deployment frequency indicates that CI/CD pipelines are mature and effective, allowing teams to release features, improvements, and bug fixes rapidly. Frequent deployments reduce risks associated with large releases, enable faster feedback loops, and support continuous delivery at scale. Monitoring deployment frequency provides insight into the organization’s ability to respond to market demands, accelerate innovation, and maintain a competitive edge.
2. Lead Time for Changes (LT)
Lead Time for Changes refers to the average time from committing a code change to successfully deploying it in production. Short lead times are a hallmark of agile, automated DevOps processes and reflect the efficiency of integration, testing, and deployment workflows. Reducing lead time enables organizations to deliver value faster, respond promptly to defects, and iterate on features efficiently. It provides a clear measure of pipeline optimization and highlights opportunities for process improvement in development and operations.
3. Mean Time to Recovery (MTTR)
Mean Time to Recovery quantifies the average duration required to restore service after a failure or incident. Low MTTR is an indicator of resilient systems, effective monitoring, and rapid incident response. It reflects the organization’s ability to maintain service continuity, minimize downtime, and recover quickly from unexpected issues. MTTR emphasizes the importance of proactive monitoring, automated recovery mechanisms, and preparedness in incident management, which are central to successful DevOps practices.
4. Change Failure Rate (CFR)
Change Failure Rate measures the percentage of changes or deployments that result in incidents, failures, or rollbacks. A low CFR reflects high-quality releases, effective testing, and mature quality assurance practices. By tracking CFR, teams can focus on improving automated testing, code reviews, and validation within CI/CD pipelines. CFR also encourages a culture of accountability, continuous learning, and risk mitigation, reinforcing the principle that speed should not compromise reliability.
5. Availability and Uptime
Availability or uptime measures the reliability of systems and the quality of user experience. High availability indicates that applications remain accessible and functional, which is critical for maintaining user trust. Tracking uptime helps teams ensure operational stability, minimize service disruptions, and improve infrastructure and application monitoring.
6. Cycle Time
Cycle Time measures the duration from idea conception or feature request to production delivery. It reflects the organization’s ability to transform requirements into valuable software efficiently. Short cycle times indicate streamlined workflows, effective collaboration, and rapid response to business needs, supporting agile and DevOps practices.
7. Automation Coverage
Automation Coverage quantifies the percentage of processes that are automated, including testing, deployment, monitoring, and infrastructure provisioning. High automation coverage reflects the maturity of DevOps practices, reduces human error, and accelerates delivery cycles. It also enables teams to focus on higher-value tasks like innovation, architecture improvement, and performance optimization.
Continuous Feedback and Improvement
Continuous feedback in DevOps refers to the systematic collection, analysis, and utilization of insights from every stage of the software development lifecycle — including development, testing, deployment, operations, and user experience. It is not limited to merely detecting failures or tracking metrics; rather, it is a comprehensive approach to learning from both successes and shortcomings. By continuously monitoring application performance, operational health, user behavior, and team processes, organizations create a feedback loop that informs decisions, drives improvements, and supports adaptive planning.
Role in DevOps
In the DevOps context, continuous feedback is essential because it enables real-time visibility and actionable insights across the software lifecycle. Feedback from automated testing, CI/CD pipelines, monitoring tools, and user analytics allows teams to identify bottlenecks, detect defects early, and make data-driven decisions. It bridges the gap between development, operations, and business stakeholders, fostering a culture of transparency, collaboration, and shared responsibility for software quality and delivery.
Benefits and Impact
Continuous feedback ensures that changes are validated quickly, issues are addressed before they escalate, and workflows are continuously optimized. It allows teams to iterate faster, improving features, performance, and stability while minimizing risks. Moreover, by integrating feedback from end-users and production systems, organizations can align software development with business objectives, ensuring that delivered features provide tangible value. This iterative learning cycle strengthens the DevOps principle of continuous improvement and empowers teams to adapt to changing requirements and emerging challenges efficiently.
Implementation in DevOps
Implementing continuous feedback involves leveraging monitoring and observability tools, automated testing results, performance metrics, and user behavior analytics. Feedback can be visualized through dashboards, alerts, and reports, allowing teams to act immediately on issues or opportunities for optimization. The integration of this feedback into CI/CD pipelines ensures that insights are not only collected but also directly influence workflow adjustments, deployment strategies, and operational policies, creating a self-improving DevOps ecosystem.
Connection to Continuous Improvement
Continuous feedback is inseparable from continuous improvement. The feedback loop provides the evidence and context needed to refine processes, enhance automation, optimize pipelines, and strengthen collaboration. It ensures that DevOps practices evolve organically, with each release or operational cycle contributing to better efficiency, reliability, and overall software quality.
Cultural Significance
Beyond technical implementation, continuous feedback fosters a culture of learning, accountability, and responsiveness. Teams are encouraged to embrace failures as learning opportunities, celebrate improvements, and remain proactive in adapting workflows. This cultural shift enhances engagement, reduces silos, and aligns technical efforts with organizational goals, making continuous feedback a cornerstone of mature DevOps practices.
Key Elements of Continuous Feedback in DevOps
Continuous feedback in DevOps is the practice of gathering insights at every stage of the software development and delivery lifecycle to drive improvements. It includes monitoring application performance, user experience, and operational metrics, as well as collecting feedback from development, QA, and operations teams. This ongoing flow of information helps teams detect issues early, optimize processes, and ensure that software meets both technical and business objectives.
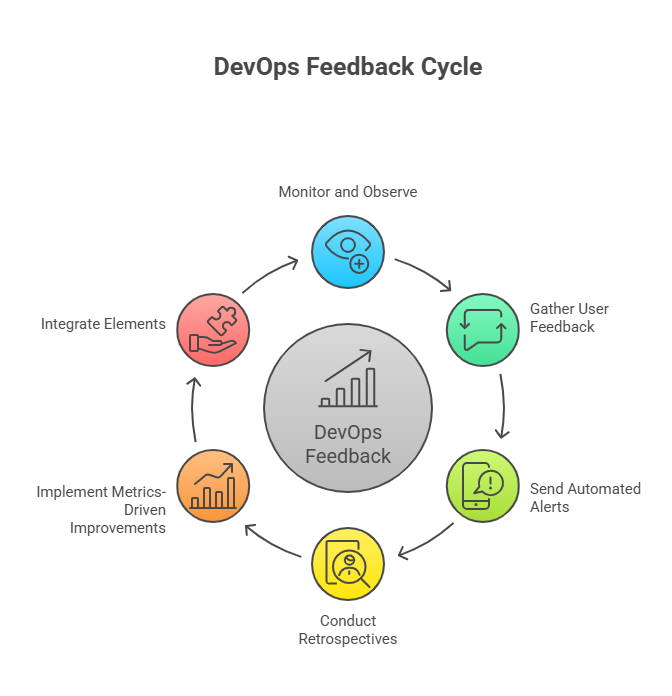
1)Monitoring and Observability
Monitoring and observability are fundamental to continuous feedback in DevOps because they provide real-time visibility into system performance, errors, and user behavior. By continuously tracking metrics such as application latency, error rates, resource utilization, and transaction volumes, teams can detect anomalies and potential issues before they escalate into critical failures. Observability goes beyond simple monitoring by enabling the analysis of complex interactions between services, dependencies, and infrastructure. This allows for proactive decision-making, informed optimization of system performance, and early intervention to prevent downtime. Monitoring and observability also create a continuous stream of operational insights that feeds back into development and operations workflows, strengthening CI/CD pipelines and overall system reliability.
2)User Feedback
Continuous collection of user feedback is another vital element of DevOps feedback loops. By integrating direct input from end-users, such as feature requests, usage patterns, bug reports, and satisfaction metrics, teams can ensure that software aligns with actual user needs and expectations. User feedback informs prioritization of new features, enhancements, and corrective actions, allowing organizations to deliver high-value functionality more quickly. It creates a bridge between technical teams and business objectives, ensuring that DevOps practices not only optimize internal processes but also enhance user experience and satisfaction.
3)Automated Alerts and Notifications
Automated alerts and notifications form a critical mechanism for immediate response in DevOps workflows. When integrated with CI/CD pipelines and monitoring tools, these alerts notify teams of failures, regressions, performance anomalies, or configuration issues. Automation ensures that incidents are detected and communicated without delay, significantly reducing Mean Time to Recovery (MTTR). By providing actionable insights in real time, automated alerts enable teams to respond proactively, minimize downtime, and maintain stability across production environments. These systems also reinforce accountability and enable continuous improvement by ensuring that issues are tracked, addressed, and prevented in future releases.
4)Retrospectives and Postmortems
Retrospectives and postmortems provide a structured approach for teams to reflect on successes, failures, and process inefficiencies. Regular team discussions encourage evaluation of what worked, what didn’t, and where bottlenecks occurred. This reflection process fosters a culture of learning, openness, and experimentation, where mistakes are viewed as opportunities for improvement rather than blame. Insights from retrospectives inform future workflow adjustments, automation enhancements, and testing strategies, reinforcing a continuous improvement mindset throughout the organization.
5)Metrics-Driven Improvements
Metrics-driven improvements are essential for quantifying the effectiveness of DevOps practices. By analyzing operational metrics, such as deployment frequency, lead time, change failure rate, and system uptime, teams can identify inefficiencies, risks, and potential areas for optimization. High lead time may indicate bottlenecks in testing or deployment, while elevated change failure rates suggest the need for enhanced automated testing or quality assurance. Leveraging these metrics ensures that decisions are evidence-based, promotes accountability, and provides actionable guidance for refining processes, optimizing pipelines, and enhancing overall software delivery performance.
6)Integration of Elements
Together, these elements—monitoring, user feedback, automated alerts, retrospectives, and metrics-driven analysis—form a cohesive continuous feedback system that drives DevOps success. They create a dynamic, self-improving loop in which data from all stages of software delivery informs development, operations, and business decisions. This integration ensures that processes are continuously refined, systems remain resilient and reliable, and software evolves in alignment with user needs and organizational goals. Continuous feedback thereby becomes the backbone of DevOps culture, enabling teams to deliver high-quality software faster, more reliably, and with measurable impact.
Relation to DevOps Principles
Continuous feedback, automation, collaboration, and iterative improvement are closely aligned with core DevOps principles. These practices ensure faster delivery, higher quality, and enhanced reliability by bridging development and operations. By embracing these principles, organizations achieve a culture of continuous learning, efficiency, and customer-focused software delivery.
1. Continuous Improvement
Continuous feedback loops enable incremental and measurable enhancements in both processes and product quality. By collecting insights from development, testing, deployment, operations, and user experience, teams can identify inefficiencies, detect issues early, and implement targeted improvements. This ensures that DevOps practices evolve continuously, fostering higher quality software, faster delivery cycles, and better alignment with business objectives.
2. Automation and Reliability
Monitoring, observability, and metrics-driven analysis empower teams to implement data-informed automation. Automated CI/CD pipelines, deployment workflows, and self-healing infrastructure reduce the likelihood of human error, improve system consistency, and increase reliability. Insights from feedback loops allow teams to continuously refine automation, ensuring more predictable and resilient software delivery.
3. Collaboration and Transparency
Metrics, retrospectives, and shared dashboards promote collaboration and transparency across development, operations, QA, and business teams. By providing a unified view of performance, failures, and process effectiveness, continuous feedback encourages shared understanding and collective ownership. Teams can align efforts, make informed decisions together, and maintain accountability throughout the software delivery lifecycle.
4. Agility and Responsiveness
Continuous feedback allows teams to respond rapidly to production incidents, user needs, and changing business requirements. By integrating real-time insights into CI/CD pipelines and operational workflows, DevOps teams can adapt deployment strategies, optimize processes, and iterate features quickly. This agility ensures that organizations remain competitive, responsive, and able to deliver value continuously in dynamic environments.

Class Sessions
1- What is DevOps?
2- DevOps Goals and Benefits
3- DevOps Lifecycle Overview
4- Continuous Integration (CI)
5- Continuous Delivery (CD)
6- Infrastructure as Code (IaC)
7- Automated Testing
8- Version Control Tools
9- CI/CD Tools
10- Containerization Tools
11- Building a CI/CD Pipeline
12- Containerization and Deployment
13- Evolution towards NoOps and Autonomous Ops
14- Low-Code/No-Code DevOps
15- Key DevOps Metrics (DORA Metrics)
16- ROI (Return on Investment) of DevOps Adoption
Sales Campaign

We have a sales campaign on our promoted courses and products. You can purchase 1 products at a discounted price up to 15% discount.