Data exploration is the first and one of the most critical stages in the data science methodology.
It acts as the bridge between raw data and the analytical techniques that follow.
Before any modeling, machine learning, or statistical inference is done, the data must be understood thoroughly at a granular level.
Data exploration helps analysts develop familiarity with the dataset by examining the nature of variables, understanding the internal structure, identifying patterns, and detecting quality issues that may impact model reliability.
Unlike later phases that involve algorithms or predictions, data exploration is purely about understanding what you have, what it means, and what challenges lie ahead.
This phase allows you to ask essential questions:
What type of data am I working with? How is the data structured? Are there issues that require attention? Is the dataset representative of the problem I’m trying to solve? These questions form the backbone of exploration.
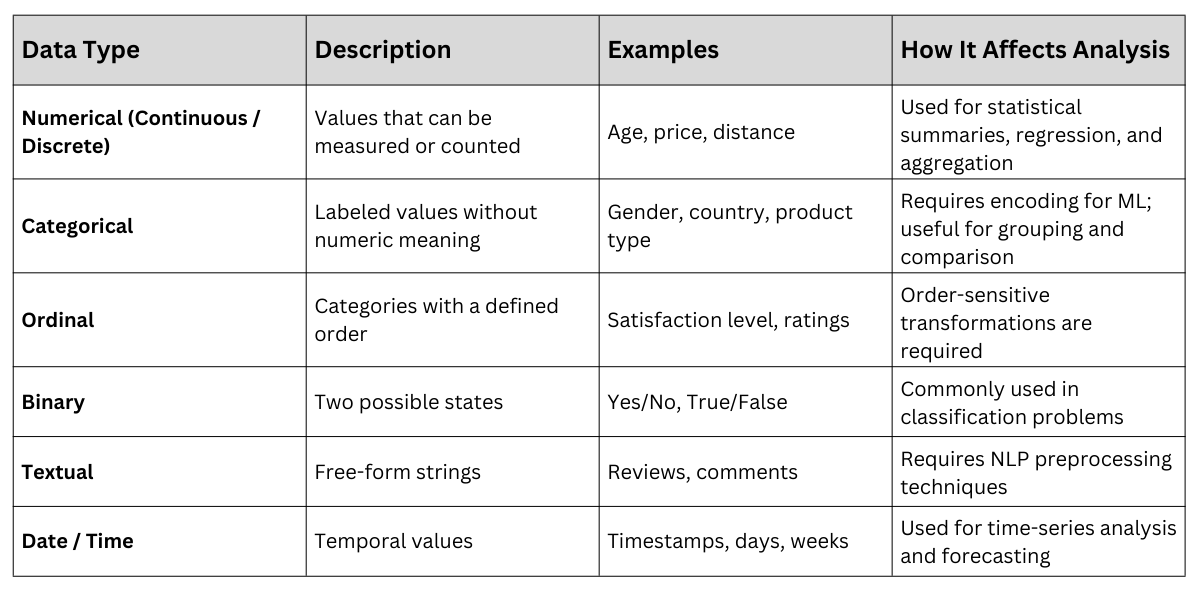
Understanding Data Types (Essential for Modeling & Cleaning)
 Understanding Data Structure (How Data Is Organized)
Understanding Data Structure (How Data Is Organized)
Understanding Data Structure explains how data is organized, stored, and formatted for analysis.
It helps beginners recognize different data types and structures so they can efficiently clean, analyze, and model data.
Exploring Structure in Practice
Data types determine the appropriate analytical methods, preprocessing steps, and model selection.
Without recognizing variable types correctly, you may end up applying methods that do not fit the data’s nature.
Understanding data types allows analysts to determine whether variables need encoding, scaling, transformation, or decomposition.
 1. Numerical variables may require normalization or scaling before modeling.
1. Numerical variables may require normalization or scaling before modeling.
2. Categorical variables require encoding such as one-hot encoding or label encoding.
3. Text data must undergo tokenization, vectorization, or embedding techniques.
Incorrect identification can lead to inappropriate models—for example, treating an ordinal variable like "education level" as nominal may distort interpretation.
The structure describes how data elements relate to each other, which determines how they should be processed.While tabular data is easiest to work with, real-world data is often messy or mixed:
1. A single column may contain multiple values (e.g., "City, Country").
2. Hierarchical data requires flattening before analysis.
3. Time-series data demands sorting and resampling.
Correctly interpreting structure helps in deciding which tools or transformations are needed.
