Model Versioning and Deployment in Advanced MLOps
Model versioning in MLOps is the systematic practice of tracking and managing different versions of machine learning models, including their code, parameters, datasets, and configuration. It ensures reproducibility, traceability, and easy rollback to previous versions in case of errors or performance degradation.
Deployment is the process of moving a trained ML model into a production environment where it can serve predictions to applications, users, or other systems. Together, versioning and deployment ensure that ML models are reliable, auditable, and continuously maintainable in production.
Model versioning and deployment are critical aspects of Advanced MLOps, bridging the gap between machine learning experimentation and reliable production-grade systems. In DevOps, version control, reproducibility, and automated deployment are foundational principles that ensure software changes are tracked, tested, and delivered reliably. MLOps extends these principles to machine learning, where the artifacts being versioned and deployed include datasets, features, trained models, and even preprocessing pipelines. Just as code in DevOps requires version control and CI/CD pipelines, ML models need structured versioning and automated deployment mechanisms to ensure stability, reproducibility, and traceability in production environments.
Model Versioning
Model versioning is the process of tracking and managing different iterations of machine learning models over time. Each trained model is considered an artifact that includes the model weights, architecture, hyperparameters, training data references, and evaluation metrics. In a DevOps-aligned MLOps workflow, versioning allows teams to reproduce results, roll back to previous stable models, and trace which dataset and configuration were used for a specific deployment.
Tools like MLflow and Kubeflow provide robust model versioning capabilities. MLflow offers a centralized model registry where each model is stored with a unique version number, metadata, and associated evaluation metrics.
This allows teams to track experiments, compare model performance, and decide which version to deploy to production. Kubeflow, on the other hand, integrates with Kubernetes and supports versioning as part of a fully automated pipeline. Models trained in different environments or with varying hyperparameters can be stored systematically, ensuring reproducibility—a core DevOps principle.
Model versioning is especially critical in DevOps environments where continuous integration and deployment are standard practices. Without proper version control, deploying a new model could overwrite a stable version, introduce regressions, or create inconsistencies in production. By maintaining multiple versions, MLOps ensures safe experimentation while safeguarding operational reliability. Additionally, versioning enables collaborative development between data scientists and operations engineers, ensuring that everyone works on reproducible, tracked models.
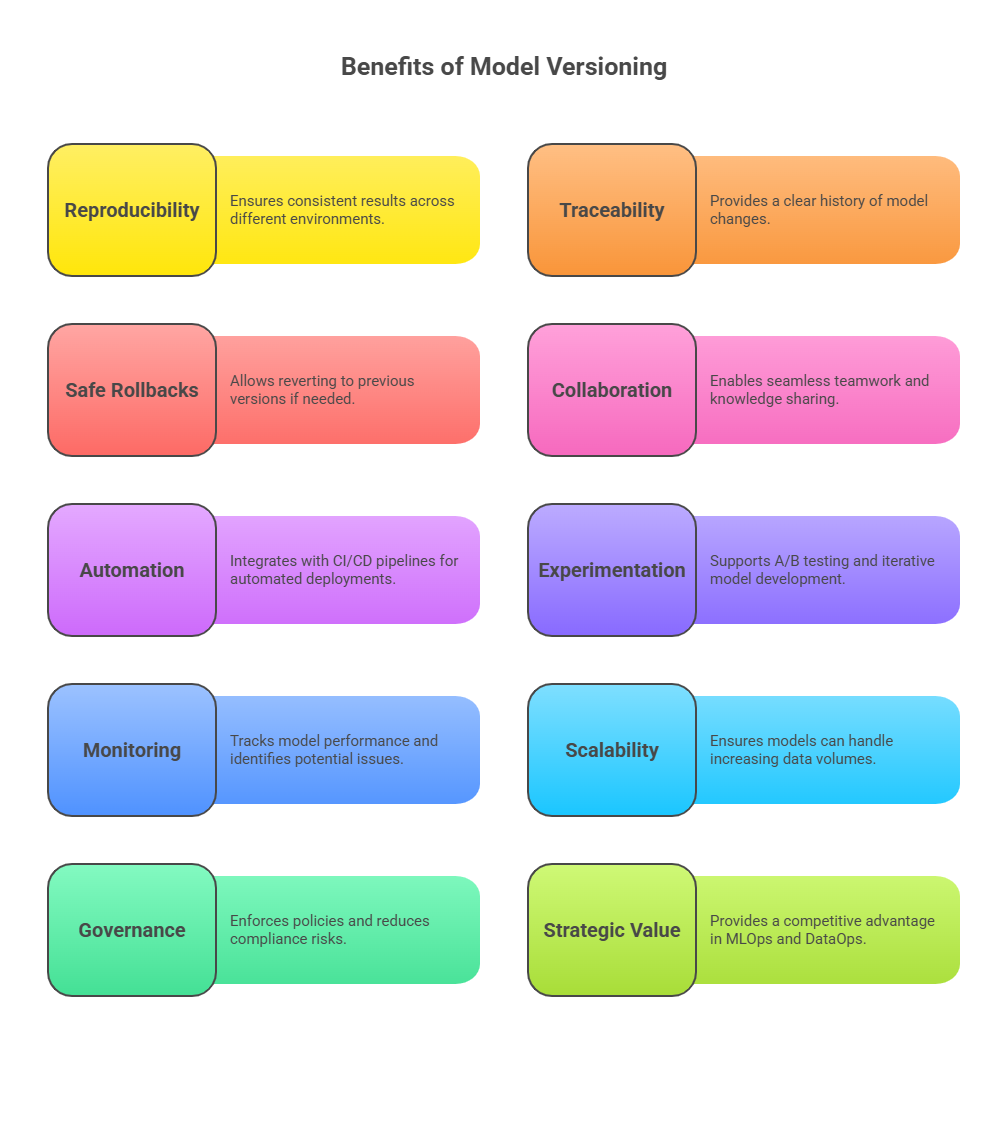
Importance of Model Versioning in Advanced MLOps and DataOps
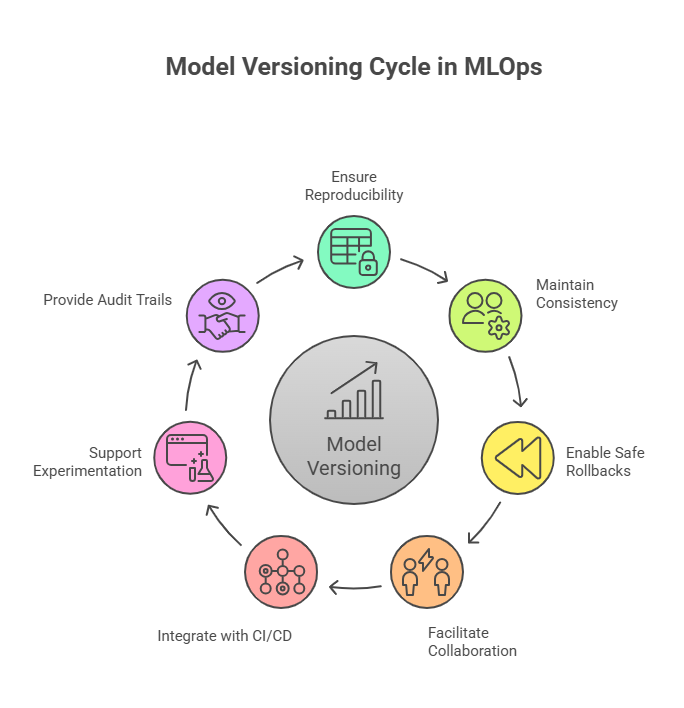
In the realms of Advanced MLOps and DataOps, model versioning plays a pivotal role in ensuring that machine learning systems and data pipelines are reliable, reproducible, and scalable. Modern ML workflows involve complex interactions between datasets, models, code, and deployment environments, often spanning multiple teams and cloud platforms. Model versioning provides a structured approach to track every change across this lifecycle, capturing not only the model itself but also the associated training data, feature engineering steps, hyperparameters, and environment configurations. By maintaining a detailed history, teams can reproduce experiments, validate results, and audit any decision made during the model lifecycle, which is critical for high-stakes, enterprise-grade AI deployments.
1)Reproducibility and Consistency
Advanced MLOps and DataOps workflows demand consistent and reproducible model outputs across multiple environments. Model versioning ensures that any version of a model can be recreated accurately, using the exact code, data, and configuration settings. This consistency supports rigorous testing, debugging, and validation, and prevents discrepancies when models are deployed to staging or production environments. Without proper versioning, reproducing previous experiments or verifying results becomes challenging, which can compromise reliability and hinder collaboration across teams.
2)Enhanced Traceability and Auditability
In regulated industries or enterprise environments, every change to models and data pipelines must be fully traceable. Model versioning logs all updates, experiments, and deployments, providing a comprehensive audit trail. This capability supports compliance with industry standards, enables thorough governance, and ensures that organizations can explain model decisions or outcomes when required. Traceability also improves accountability, allowing teams to track contributions and modifications across complex, multi-team workflows.
3)Safe Rollbacks and Risk Mitigation
Production models are constantly evolving to incorporate new data or updated algorithms, but not all deployments perform as expected. Model versioning allows teams to revert to a previously validated version instantly if a new model underperforms or introduces errors. This minimizes downtime, reduces operational risk, and ensures business continuity. In DataOps environments where data pipelines feed ML models in real time, safe rollback mechanisms become even more critical to prevent cascading errors from affecting downstream analytics or decision-making systems.
4)Facilitates Collaboration Across Teams
Model versioning is essential for seamless collaboration among data scientists, ML engineers, DevOps teams, and data engineers in Advanced MLOps and DataOps setups. Multiple teams can work on experiments, feature engineering, and deployments simultaneously without overwriting or conflicting with each other’s work. Centralized versioning ensures organized workflows, consistent codebases, and harmonized data pipelines, fostering transparency, communication, and shared ownership of AI solutions.
5)Integration with CI/CD and Automated Workflows
Advanced MLOps and DataOps leverage CI/CD pipelines to automate the testing, validation, and deployment of both models and data pipelines. Model versioning integrates tightly with these pipelines, ensuring that only tested and approved versions move to production. Automated workflows reduce manual errors, accelerate iteration cycles, and maintain high reliability across multi-stage environments. This integration also enables reproducible experimentation, continuous monitoring, and real-time validation of deployed models.
5)Supports Experimentation and Continuous Improvement
With proper versioning, teams can run multiple model experiments, compare results across different configurations, and track performance metrics over time. This encourages innovation, accelerates model optimization, and allows data-driven decisions about which versions to deploy. In DataOps pipelines, where data transformations and feature engineering steps are constantly evolving, model versioning ensures that these experiments remain reproducible and traceable, allowing teams to fine-tune both models and data workflows efficiently.
6)Monitoring, Feedback, and Performance Management
Versioned models enable granular monitoring of performance, drift, and latency in production environments. Teams can compare versions to detect degradation, bias, or errors, enabling proactive remediation and continuous improvement. In Advanced MLOps, where models may operate across multiple environments or microservices, versioning ensures that monitoring and feedback mechanisms are accurate and actionable, preventing misinterpretation of results or unintended consequences from untracked changes.
7)Scalability and Safe Rollouts
Model versioning allows enterprises to safely manage staged rollouts, A/B tests, or canary deployments. Multiple versions can coexist, enabling experimentation in production without risking system stability. This is particularly important in DataOps environments, where real-time data streams and automated pipelines require careful management to prevent downstream errors from affecting critical business operations.
8)Governance, Compliance, and Risk Reduction
In advanced MLOps and DataOps frameworks, governance and regulatory compliance are critical. Model versioning ensures that all updates, experiments, and deployments are auditable, documented, and aligned with organizational or industry standards. By maintaining a structured history of models and pipelines, organizations can reduce operational risk, enforce governance policies, and maintain trust in AI systems.
9)Strategic Value in Advanced MLOps and DataOps
Overall, model versioning in Advanced MLOps and DataOps is more than a technical requirement—it is a strategic enabler. It ensures reproducibility, collaboration, compliance, and operational stability while supporting rapid experimentation and continuous improvement. By integrating versioning with CI/CD pipelines, monitoring systems, and automated data workflows, organizations can scale AI and analytics initiatives safely, maintain reliability, and accelerate business value creation through adaptive, data-driven models.
Model Deployment
Model deployment in MLOps refers to the process of making a trained machine learning model available for inference in production environments. Unlike traditional software deployments, model deployment involves considerations such as serving predictions at scale, handling real-time or batch inference, and integrating with existing DevOps infrastructure. Deployment pipelines must ensure that models are not only correct but also performant, secure, and resilient.
Tools like Seldon, Kubeflow Serving, and MLflow facilitate automated, scalable model deployment within DevOps-aligned pipelines. Seldon provides a platform for deploying, scaling, and managing machine learning models on Kubernetes clusters, supporting advanced features like A/B testing, canary releases, and rolling updates. This is analogous to how DevOps pipelines handle software services, ensuring minimal disruption when new model versions are deployed. Kubeflow Serving enables seamless deployment of models from the Kubeflow pipeline to Kubernetes, integrating monitoring and logging to track inference performance.
MLflow’s deployment APIs allow models to be served locally, on cloud infrastructure, or containerized environments with built-in version tracking.Automated deployment in MLOps mirrors the CI/CD approach in DevOps. Just as DevOps automates software build, test, and release cycles, MLOps pipelines automate model packaging, testing, and deployment. Before a model is released to production, automated checks verify its accuracy, performance, and compatibility with the serving environment. Post-deployment, continuous monitoring ensures that the model behaves as expected under live conditions. If performance drops due to concept drift, automated retraining pipelines can trigger the deployment of updated versions, maintaining reliability and aligning with DevOps principles of continuous improvement and automation.
Importance in DevOps-Aligned MLOps
Model versioning and deployment are essential to integrating machine learning into DevOps workflows. Versioning ensures reproducibility, traceability, and safe experimentation, preventing errors or inconsistencies in production. Deployment automation ensures that models are released efficiently, with minimal human intervention, high reliability, and scalable performance. By combining these practices with DevOps principles like CI/CD, infrastructure as code, and monitoring, organizations can treat ML models as first-class production artifacts.
Moreover, versioned models integrated with deployment pipelines enable rollbacks, A/B testing, and gradual rollouts, which are standard in DevOps for managing software releases. This allows organizations to release new models safely, compare their performance against previous versions, and minimize operational risk. Monitoring post-deployment ensures that models maintain expected behavior, and metrics from inference workloads provide feedback to refine both the models and the pipeline.
In essence, model versioning and deployment in Advanced MLOps ensure that machine learning systems are reliable, reproducible, and scalable, fully embracing DevOps principles. Tools like MLflow, Kubeflow, and Seldon bridge the gap between data science experimentation and operational excellence, enabling organizations to deploy production-grade AI systems with confidence. This integration transforms DevOps pipelines into intelligent, data-driven ecosystems where software and AI models co-exist, continuously improve, and deliver consistent value in production environments.

Class Sessions
1- Introduction to DevOps Culture
2- DevOps Lifecycle Stages
3- Key Tools and Environments
4- Git Essentials
5- CI/CD Integration with Repositories
6- AWS DevOps Tools
7- Azure and GCP DevOps
8- Multi-Cloud & Hybrid Deployments
9- Introduction to AIOps
10- Predictive Analytics for DevOps
11- AI-Driven Continuous Testing
12- ChatOps and Intelligent Automation
13- MLOps Pipeline Fundamentals
14- Model Versioning and Deployment
15- Introduction to Future-Proof DevOps Practices